
本文为自己整理的Verilog快速上手笔记,笔记借鉴了夏宇闻老师的 《Verilog数字系统设计教程》,以及自己对verilog的一些理解,也借鉴了网络上的一些关于verilog的资料整理而来
因为笔记比较简单,而verilog本身又比较庞大,加上自己能力也有局限,所以仅供没有verilog基础的人快速了解之用, 如需深入系统的学习verilog 还是建议大家看完整的verilog书籍来系统学习最佳
另外 虽然verilog在很多语法上和c语言非常类似 ,但是一定要记住 verilog是一门硬件描述语言,请把它和软件编程语言区分开,因为你所写的每一个逻辑都会最终对应成实实在在的硬件资源的
资料写的虽然浅显,但是也是花了好些日子整理的,大家有什么疑问直接 在网站下方留言即可,看到会回复 后续有精力会整理具体的verilog 小模块例子
资料整理在网站hellofpga.com下,如转载请注明出处
模块的结构
Verilog设计的基本单元是模块”module” 也称作(block),模块由两部分组成,一部分描述接口,另一部分描述逻辑功能(逻辑功能即模块的功能,即输入如何影响输出)
1 module and_block( 2 input A , 3 input B , 4 output Y 5 ); 6 7 assign Y = A & B; 8 9 endmodule
上面描述了一个与门的完整模块,我们着重关注下代码的结构
- 模块由 module 开始 ,由endmodule 结束
- module 后跟着的是模块名,这里是and_block(这里名称可以根据设计的功能自行更改)
- 模块声明的括号中的是 端口信号,其中input代表输入信号,output代表输出信号,inout代表双向输入输出口,每一个信号以”,”来划分, 最后一个信号 不加任何标点
- 模块的逻辑功能部分(模块的功能,即输入如何影响输出,这里是Y = A & B)
- 模块声明结束后 必须要在右括号后增加分号“;”
上述代码的功能很简单,实际的功能就是 输出y的结果 等于 输入a和b的相与,其功能就相当于下图的与门功能

其实模块的声明有多种方式 同样拿上面的代码来举例 申明可以是下面两种形式
1 module and_block( 2 input A , 3 input B , 4 output Y 5 );
1 module and_block(A,B,Y); 2 input A ; 3 input B ; 4 output Y ;
上面两种方式都是可以的,区别就是在申明的时候定义端口类型, 还是先申明有哪些信号后,再在后面描述端口的类型
注意,上述的A ,B 和 Y信号都是1位的, 大部分使用场合输入输出信号都不止1位的时候,那定义接口类型的时候就要按下述方法来定义了
input [信号位宽-1:0]端口名; 输入口
output [信号位宽-1:0]端口名; 输出口
inout [信号位宽-1:0]端口名; 输入/输出口
举个例子
input [2-1:0]A; 就是定义了一个2个bit位宽的 输入信号A
备注(没有说明reg 或者 wire类型的时候, input output 默认定义的A都是 wire类型的)数据类型 常量
1.数字类型
在Verilog HDL 中,整形常量有以下四种表示方式
- 二进制 b或B
- 十进制 d或D
- 十六进制 h或H
- 八进制 o或者O
数字的表示方式一般由 <位宽><进制><数字>形式进行描述 举几个例子
8’d128 8代表8bit 位宽(后边跟一个符号 ‘ ),d代表十进制 ,128代表十进制的128的意思
8‘b00000001 同样代表 8bit的 二进制的 00000001(其值等同于 8’d1 即8bit十进制的1)
但是 8’d500 这个就是错误的,因为500对应的 二进制是 111110100 一共是9位,已经超过8位位宽了,8bit的范围只能是0-255 ,这里要特别注意,否则写程序的时候容易溢出
2. x和z 值
在数字电路中,除了0和1以外,还有另外两种情况,那就是 不定值 和高阻态, 其中x 代表不定值, z代表高阻态,对于没有进行初始化的信号,一般处于不确定值 x(仿真的时候经常会出现),高阻态表示该信号没有被其他信号驱动(可以简单理解为悬空状态)
x和z 在二进制中代表1位,在八进制中代3位x或者z,在十六进制中代表4位x或者z
3. 下划线 _
下划线只是用来提高代码的可读性的,当一串数字比较长的时候 我们就可以用下划线来进行分割
比方说25’d50_000_000 这里其实等同于25’d50000000只是代码可读性更强了
4. 参数parameter
可以理解为C语言中定义的常量,parameter 参数名=数值
如 parameter a=25;
数据类型 变量
变量 (即程序运行过程中其值可以改变的量)常用的变量的数据类型有 reg ,wire
wire型
wire 可以理解为物理连线,即只要输入有变化,输出马上无条件地反映,不能保存数据,而且必须收到驱动器(如门或者连续赋值语句assgin)的驱动。
wire [n-1:0]数据名; n-1代表数据的位宽是n位 ,数据名代表数据的名称 举个例子
wire [8-1:0]a ; 定义了一个8位的wire型数据,并且命名为a
如果只定义1位的wire型 就不需要定义位宽 比方说
wire b; 就代表定义了1位的wire型reg型
reg代表寄存器,寄存器只有才在触发的条件下才能改变值,没有输入的时候可以保存原来的值(即寄存器可以在下一次触发之前锁存当前的数据)
reg和wire的区别是 :reg可以保持最后一次的赋值,而wire数据需要持续的驱动 wire 通常需要assign 语句进行连接, 而reg 一般需要在 initial 和always 块中进行赋值 (在“always”块内被赋值的每一个信号都必须定义成reg型)
reg的定义同wire型相似
reg[n-1:0]数据名; n-1代表数据的位宽是n位 ,数据名代表数据的名称 举个例子
reg [8-1:0]a ; 定义了一个8位的reg型数据,并且命名为a
如果只定义1位的reg型 就不需要定义位宽 比方说
reg b; 就代表定义了1位的regmemory型
verilog 通过对reg型变量建立数组来对存储器建模,从而描述ram或者rom存储器。数组中的每一个单元通过一个数组索引进行寻址。在Verilog语言中没有多维数组存在。(memory型数据是通过扩展reg型数据的地址范围来生成的)
reg [n-1:0] 存储器名[m-1:0];
其中reg[n-1:0]定义了存储器中存储单元的位宽为n,而[m-1:0]则定义了又多少个这样的存储单元
备注 reg[n-1:0]a; 代表一个n位的寄存器 reg a[n-1:0]a;代表n个1位的存储器 不要弄混了运算符及表达式:
1) 算术运算符(+,-,×,/,%)
用法和C语言比较类似,但是值得注意的是,在进行算数运算操作时,如果某一个操作数有不确定的值x,则整个结果也为不定值x 另外,Verilog直接实现乘除比较浪费组合逻辑资源,实际项目中会用FPGA的DSP资源来代替乘除法,或者用2的指数次幂的乘除法直接用移位的方式来替代
2) 位运算符(~,|,^,&,^~) 和C语言比较类似
~ //取反 对一个操作数进行按位取反 & //按位与 将两个操作数的对应位进行与运算 | //按位或 将两个操作数的相应位进行或运算 ^ //按位异或(XOR) 将两个操作数的相应位进行异或运算 ^~ //按位同或(异或非) 将两个操作数的相应位进行异或运算再进行非运算
3) 逻辑运算符(&&,||,!) 和C语言比较类似
&& 逻辑与 参与运算的两个数都为真时, 结果才为真 || 逻辑或 参与运算的两个数其中任意一个为真,结果就为真 ! 逻辑非 对参数进行取反,与~不同的是~是一位一位取反,而!是对整个数据取反,如果 这个数取反前不为零,取反后就是零,如果这个数取反前是零,取反后就是1
4) 关系运算符(>,<,>=,<=) 和C语言用法比较类似
一共有4种 a<b a>b a<=b a>=b 如果判断的关系是假,则返回0,如果判断的关系为真,则返回为1 如果某个操作数的值不定,则返回值也是不定值
5)等式运算符
== //等于 != //不等于 === //等于 !== //不等于 其中 == 和!= 如果操作数中含有不定值 x 则结果也是x 而 === 和!=== 比较的过程中连某些位的x和z也会进行比较,也就是操作数每一位都完全一致,结果才是1,否则为0
6) 移位运算符(<<,>>) 和C语言用法比较类似
<< 左移运算符 数据低位补0 >> 右移运算符 数据高位补0
7) 拼接运算符({ })
可以把两个或多个信号的某些位拼接起来作为一个新的信号
{a[2:1],b[5:3]} 即相当于把a的2到1位,b的5到3位拼接起来了 结果等同于{a[2],a[1],b[5],b[4],b[3]}
8) 条件运算符(?:)
条件运算符可根据条件语句的真假 来将不同的信号进行输出 要使用条件运算符,需要在 ? 运算符之前写一个逻辑表达式,然后判断它是真还是假。根据表达式的真假将两个值中的某一个赋值给输出 输出 = 条件 ? 真的情况 : 假的情况 ; 如 a = (c > b) ? c : b; //如果c大于b,则a等于c;否则a等于b
9) 赋值运算符(=,<=)
<= 非阻塞赋值 用于时序逻辑 = 阻塞赋值 用于组合逻辑 非阻塞(Non_Blocking)赋值方式( 如 b <= a; ) 在语句块中,上面语句所赋的变量值不能立即就为下面的语句所用 块结束后才完成赋值操作,而所赋的变量值是上一次赋值得到的 备注 :非阻塞赋值 <=与 运算符 小于等于 意义完全不同,一个用于比较大小,一个用于赋值,不要混淆 阻塞(Blocking)赋值方式( 如 b = a; ) 赋值语句执行完后,块才结束 b的值在赋值语句执行完后立刻就改变的 在时序逻辑中使用时,可能会产生意想不到的结果。
块语句
(1)顺序块:begin-end
begin end 可以很简单 也可以很复杂,如果你只是希望学会如何使用那很简单,你只需要把它当作C语言中函数的大括号就可以了
always@(posedge clk)begin
if(a==0)begin
……
end
else begin
……
end
end
仔细观察 上面这个简易代码,是不是发现 和C的大括号使用场景几乎一致? 其实对于大多数人来说知道这个就好了
如果需要深究,这里有点点复杂, 首先称呼begin end 为顺序块 是因为begin end 块内的语句是按顺序执行的,即只有上面一条语句执行完成后下面的语句才执行, 但是这又和我们实际写代码时候有点区别 (大多数人的印象是 begin end 中的语句明明也是并行的呀,别着急,看下面)
这个问题是分两种情况的
1.当begin end 中是试用阻塞赋值的组合逻辑时,内部的程序将是一条执行完,再执行下一句,即顺序执行
2.当begin end 块内使用的是非阻塞赋值<= 的时序逻辑时,此时begin end 时,块内所有的语句会在模块完成时被同时执行,也就是并行执行了,所以在非阻塞赋值中 begin end 可以当作是非顺序的
有点绕,其实对于入门来说没必要深究的太多,就知道 begin end 充当花括号的角色就好
(2)并行块:fork-join 因为这个语句不可综合,所以这里不详细展开
赋值语句
verilog有三种赋值方式 1.assign 方式 2. always 方式 3.initial 方式
assign 方式 assign 是一种持续赋值语句,主要对wire型变量进行赋值,但是因为wire型变量没有保存值,所以只要输入有变化,输出马上无条件地反映 例如 assign a=b+c; 只要b和c发生变化了,a立刻也发生变化了 (这里 b 和 c可以是reg或者wire型变量,但是a必须是wire 型的)
always 方式 主要用于reg 型变量的赋值 ,因为always块是需要满足一定的触发条件才会执行的,所以里面被赋值的数据类型必须是有存储数据功能的reg 类型。 always@ (触发事件),根据括号内的触发事件的类型可以分为 电平触发,和 边沿触发 由电平触发的时候 ,通常被当作组合逻辑来使用,赋值用阻塞赋值(=) 用时钟边沿来进行触发,通常被当作时序逻辑来使用,赋值语句用非阻塞赋值(<=) 例1 用always模块的组合逻辑 reg a; reg b; reg c; always @(b or c)begin a=b+c; end always符合电平触发的组合逻辑,当b和c有变化的时候,a就会立刻跟着变化 这里always@(b or c) 也可以用 always@(*)来替代,意思是always模块中的任何一个输入信号或电平发生变化时 例2 用always模块的时序逻辑 reg a; reg b; reg c; always @(posedge clk)begin a<=b+c; end 括号内的 posedge clk 是上升沿触发, 如果要改成下降沿触发 则用negedge clk 如果有多个触发条件 ,则中间用or 来间隔 比方说always@(posege clk or negedge rstn) always符合边沿触发的时序逻辑,触发条件变成clk始终的上升沿了,每当时钟出现上升沿,模块内的语句就会被执行一次 1. 因为每次只有时钟来的时候a才会变化,所以a的数据每次会被锁存一个clk的时钟周期 2. a<=b+c;当模块被执行完后才会被赋值,如果always模块内有多个赋值语句,则多个赋值语句将被同时刷新赋值 3. 在上升沿没出现的时候 b和c无论如何变化,对a都不会产生影响(这里和电平触发有区别) always模块使用的注意事项 1.不要在同一个always块里面混合使用 阻塞赋值 和 非阻塞赋值 2.不要在两个或两个以上always块里面对同一个变量进行赋值(因为各个always 块是相互并行运行的,对同一个变量赋值会发生冲突)
initial方式
代码块只在系统运行的最初执行一次。一旦initial块中的所有语句被执行,initial块的执行就结束了。
大多数的正式教程上都描述了,initial这个语法,称其是在仿真的开始给寄存器变量类型初始化赋值用的,因此理论上是不可综合的
但是实际使用过程中,各家芯片厂商的编译器都可以综合initial这个语句用来给寄存器变量赋初始值
比方说
reg [1:0]dat;
initial begin
dat = 2'd2;
end
上述程序实际在编译器中是可以编译综合通过并下载到芯片里工作的
这样系统上电后 dat就被赋值成了2了,使用initial 初始化寄存器的方法还是挺常见的
我也不知道为什么各个教程都称其不可被综合,不过任何书籍,都不如实践得出的结论更权威对吧
条件判断语句
条件判断语句 有 if else 和 case
if else 用法和 C语言非常像 用法有如下三种 1. if(表达式)执行语句 2. if(表达式1)执行语句1 else 执行语句2 3. if (表达式1)执行语句1 else (表达式2)执行语句2 …… else (表达式n-1)执行语句n-1 else 执行语句n 表达式结果为真,则执行对应语句 几个注意的地方 1. 条件语句必须在过程块中使用 always 或者 initial 中 2. 表达式 结果如果为0,x,z 都按假处理 3. C 语言中的 if(0<A<5)在 verilog 中不能直接写,必须写成 if((0<A)&&(A<5)) 4. if else 有明显的优先级, case 是并行的没有优先级 5. if 记得加上else,避免生成不想要的锁存器
case
case 语句是一种多分枝选择语句,和if else 多层级的使用效果类似,但是if else 生成的逻辑会更繁琐一些,所以当结果需要多分支选择的时候用case 语句更合适一些
case(表达式)
分支表达式:执行语句
default:执行语句
endcase
一个简单的case 例子:
reg[2:0]rega;
reg[2:0]result;
always@(posedge clk)begin
case (rega)
3'd0: result<=3'd7;
3'd1: result<=3'd6;
3'd2: result<=3'd5;
default :result<=3'd0;
endcase
end
代码很容易看懂, 如果rega 的值当前为3'd0,则 result的值被选择为3'd7,如果rega的值不为3'd0,3'd1,3'd2,则执行defualt中的 result=3'd0;
因为这里引入了 posedge clk ,所以这里是一个时序逻辑电路,并且所有的结果都锁存一个周期输出
1.case 括号内的表达式为控制表达式, 下面分支项的表达式为分支表达式
2.当控制表达式与分支表达式的值相等时,则执行对应的分支表达式后面的语句,如果所有的分支表达式都没有和控制表达式匹配,则执行default后面的语句
3.一个case语句中只准有一个default项
4.分支执行语句可以用begin end来进行分组,里面一次性执行多条语句
注意事项
1.每一个分支项的分支表达式必须互不相同,否则就会出现问题
2.执行完某一分支的语句后,则跳出case结构,终止其他case语句的执行
3.case 语句表达式值得位宽必须相等
4. 另外 不使用default语句,容易造成系统自动生成预期以外的锁存器
如 之前上面的例子,如果去掉defualt ,就会造成当rega为 3'd3 3'd4 3'5等情况下,值result 被保持,综合成电路就是生成了额外的锁存器
case (rega)
3'd0: result<=3'd7;
3'd1: result<=3'd6;
3'd2: result<=3'd5;
endcase
为了避免生成锁存器 ,最好的方法就是 if语句 都加else case语句都加 default
模块例化
模块例化,即模块的实例化,与C语言的函数调用比较类似(注意,不能完全理解为模块的调用,因为模块的例化是实实在在生成相应的逻辑的,例如同一个模块被例化3次,则在FPGA内部,实际生成了3份相同模块的逻辑电路,所以称作模块的实例化,简称例化) 模块可以在其他模块中进行例化,并且这些实例后的模块可以通过端口,与上层模块进行信号的连接 模块例化 在verilog自顶向下的框架开发下可以说是必不可少的
举例说明
这里设计两个模块 为了方便理解,这里两个模块分别用了最最简单的 按位或,和按位取反功能 模块Bit_AND 功能很简单 核心逻辑就是 assign C=A&B;,相当于C的值等于A与B的按位与 module Bit_AND( input [7:0]A, input [7:0]B, output [7:0]C ); assign C=A&B; endmodule 模块Bit_OR 功能很简单 核心逻辑就是 assign C=A|B;,相当于C的值等于A与B的按位或 module Bit_OR( input [7:0]A, input [7:0]B, output [7:0]C ); assign C=A|B; endmodule 接下去是顶层模块分别对两个模块进行例化, 并将例化后的结果进行相加,并作为输出信号进行输出 module TOP_module( input [7:0]A_top, input [7:0]B_top, output [7:0]C_top ); wire [7:0] C_U1; Bit_AND U1( .A (A_top), .B (B_top), .C (C_U1) ); wire [7:0] C_U2; Bit_OR U2( .A (A_top), .B (B_top), .C (C_U2) ); assign C_top=C_U1+C_U2; endmodule
这个是 根据上述逻辑生成的rtl 图,可以由图上得到,TOP_MODULE中分别实例化了一个Bit_AND模块(实例名 U1),以及Bit_OR模块(实例名 U2),并且最终两个模块的输出进行相加的和是整个顶层模块TOP_MODULE的输出信号C_top
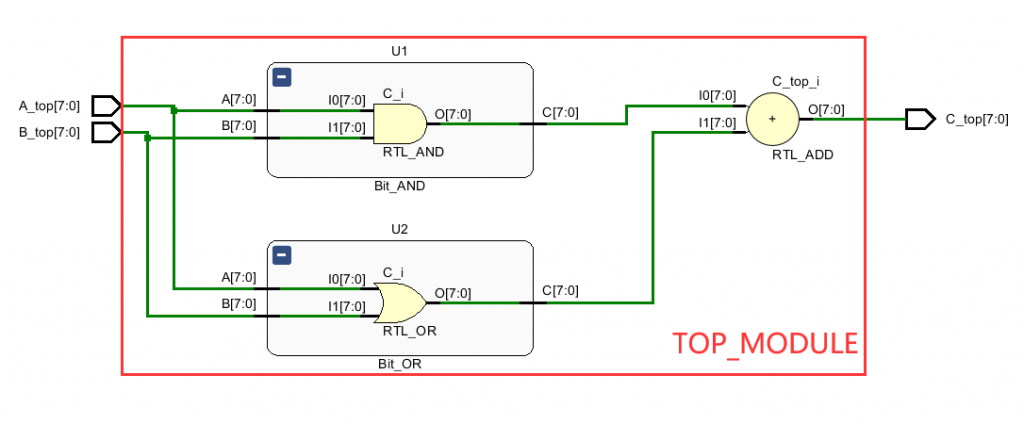
Bit_AND U1( .A (A_top), .B (B_top), .C (C_U1) ); 这句是上面例中的 Bit_AND 例化, 其中Bit_AND 是要例化的模块, U1是Bit_AND例化后的实例名称 .表示点后面的模块端口名。下一个括号()中给出了跟这个端口连接的信号
以上是我简单整理的VERILOG的语法笔记 ,笔记比较简单,仅供大家能够快速对verilog有个概念并能看懂别人的写的代码之用,另外学习Verilog其实没有捷径,只有不断的动手实践,不断地踩坑才能理解其中地奥秘地。
另外本文仅对verilog常用地一些语法进行介绍,如需深入系统的学习verilog 还是建议大家看完整的verilog书籍来系统学习最佳
另外 虽然verilog在很多语法上和c语言非常类似 ,但是一定要记住 verilog是一门硬件描述语言,请把它和软件编程语言区分开,因为你所写的每一个逻辑都会最终对应成实实在在的硬件资源的
资料写的比较浅显,大家有什么疑问直接在网站下方留言即可,看到会回复
本文整理在网站hellofpga.com下,不定期更新
好,非常好
超级棒!!!
很有帮助,感谢!
寥寥几句话就勾勒出verilog的脉络。确实厉害,也确实能看出来很用心
感谢支持,整理的比较简单